Как создать цифровой архив сайтов
Есть разные способы сохранения копии сайта, как готовые интерфейсы приложений, так и утилиты (CLI) для скачивания через командную строку.
🚨 Экстренная ситуация? Если времени мало, используйте Быстрый старт: архивация за 5 минут или перейдите к разделу Экстренные сценарии ниже.
Быстрое сохранение отдельных страниц
Для сохранения одной или нескольких веб-страниц можно использовать простые онлайн-сервисы:
Метод 1: Archive.org (Internet Archive)
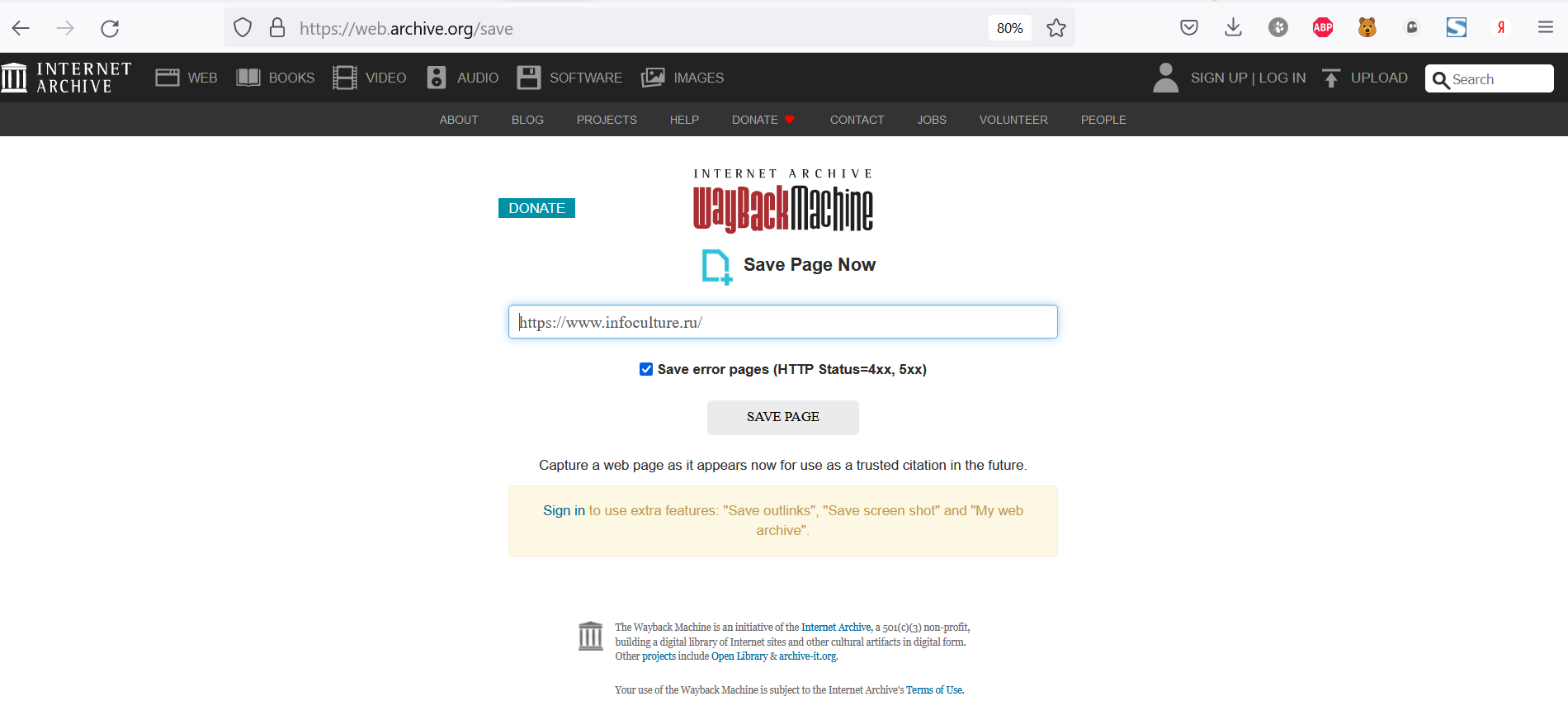
Сохранить через веб-интерфейс Интернет Архива (Archive.org). Форму «Save Page Now» для сохранения веб-страницы можно найти на этой странице. Пошагово:
- Перейдите по ссылке: https://archive.org/web/.
- Вставьте URL-адрес страницы, которую вы хотите заархивировать, в поле Save Page Now (внизу справа).
- Нажмите на кнопку Сохранить страницу (или нажмите клавишу Enter).
- Подождите, пока страница будет просматриваться. После завершения процесса архивирования появится URL-адрес заархивированной страницы.
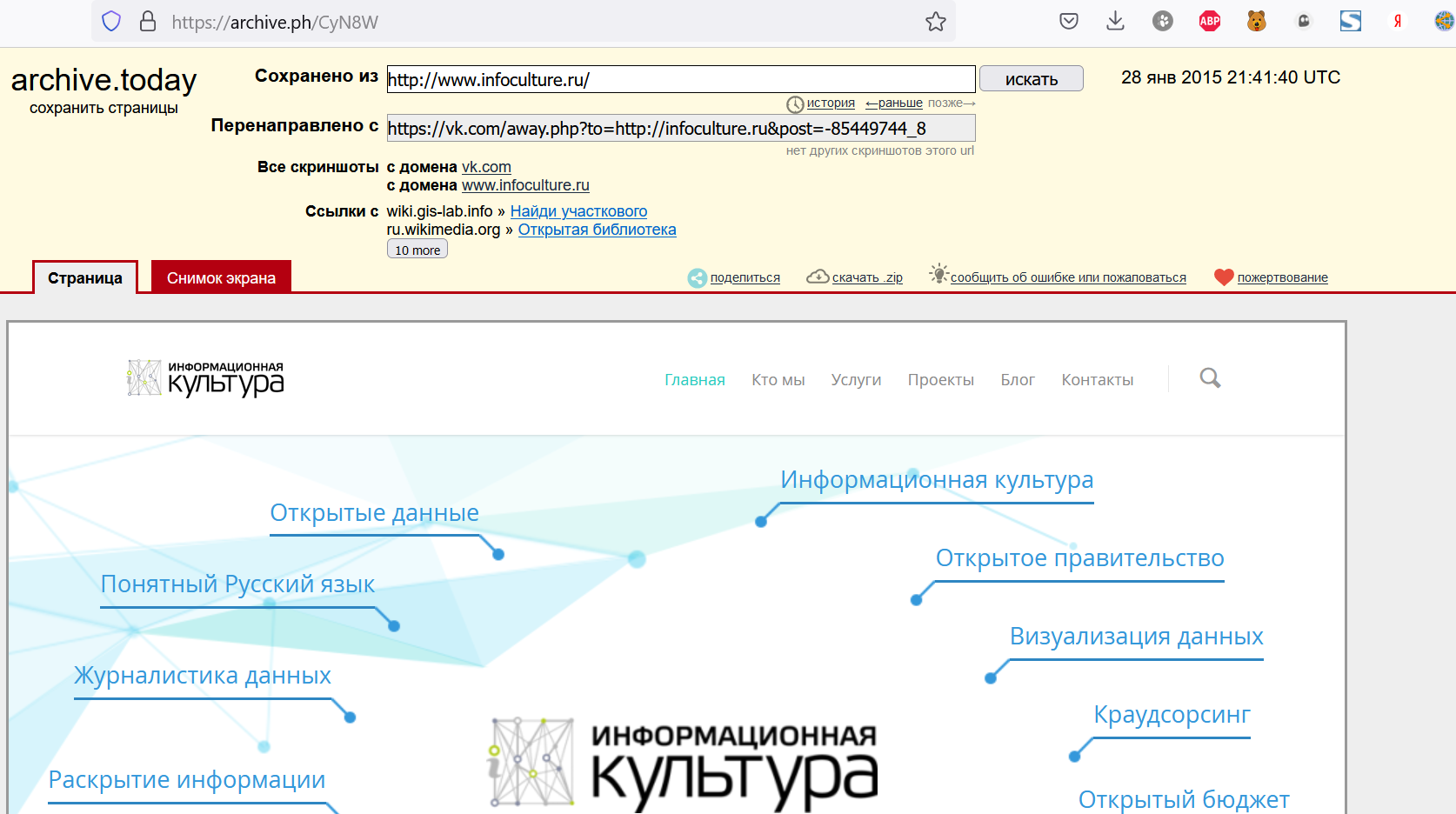
Метод 2: Archive Today (archive.ph)
Проект сохраняет текстовую и графическую копии веб-страницы и обеспечивает url-ссылку на неизменную запись любой веб-страницы.
На главной странице сервиса можно ввести ссылку на веб-страницу и она будет сохранена. А если сайт многостраничный, то в таком случае сохранить его содержимое поможет расширение для браузера Firefox.
Примечание: Эти методы подходят для сохранения отдельных страниц или небольших сайтов. Для полной архивации сайта используйте инструменты, описанные ниже.
Сравнение инструментов: что выбрать?
| Инструмент | Скорость | Сложность | Качество | Когда использовать |
|---|---|---|---|---|
| Archive.ph | ⚡⚡⚡ 30 сек | ★☆☆ | ⭐⭐ | Одна страница, срочно, нет установки |
| HTTrack | ⚡⚡ часы | ★☆☆ | ⭐⭐⭐ | Целый сайт, есть GUI, для начинающих |
| Wget | ⚡⚡ часы | ★★★ | ⭐⭐⭐⭐ | Автоматизация, продвинутые настройки |
| Wpull | ⚡⚡ часы | ★★★ | ⭐⭐⭐⭐ | Сложные сайты, WARC-формат |
| Browsertrix | ⚡ дольше | ★★☆ | ⭐⭐⭐⭐⭐ | JavaScript-сайты, интерактивность |
Быстрый выбор:
- 📄 Одна статья/страница → Archive.ph
- 🏠 Небольшой сайт (<1000 страниц) → HTTrack или Wget
- 🏢 Большой/сложный сайт → Wget или Browsertrix
- ⚡ Экстренно → Archive.ph + экстренные сценарии
Экстренные сценарии
Когда счет идет на минуты
Если сайт может быть заблокирован или удален в ближайшее время:
1. Первые 30 секунд - сохраните главные страницы через Archive.ph:
# Откройте archive.ph и сохраните:
- Главную страницу
- Страницу "О нас" / "About"
- Ключевые статьи/материалы
- Страницу контактов
Подробнее: Archive.ph: полное руководство
2. Первые 5 минут - запусти�те быструю архивацию всего сайта:
# С помощью wget (быстрая команда):
wget --mirror --convert-links --adjust-extension \
--page-requisites --wait=0.5 --limit-rate=200k \
--no-parent https://site-to-save.com
⚠️ Важно: Эта команда качает быстро, но может пропустить некоторый контент. Для полноты используйте детальную настройку ниже.
3. Если есть 1-2 часа:
Используйте HTTrack (графический интерфейс) - см. раздел HTTrack ниже.
Полный гайд по экстренной архивации: Экстренная архивация: когда счет идет на часы
HTTrack
HTTrack — это бесплатное (GPL, libre/ free software) и простое в использовании приложение, которое позволяет загрузить веб-сайт в локальный каталог, получая HTML-код страниц, изображения и другие файлы с сервера на ваш компьютер. Есть режим рекурсивной выгрузки всех страниц.
HTTrack упорядочивает относительную ссылочную структуру оригинального сайта. Приложение имеет GUI и работает под Windows, MacOSX, Linux.
Для использования приложения не нужна специальная техническая подготовка и навыки программирования, однако это приложение также работает и с командной строки (гайд пользователям).
Утилиты командной строки (CLI)
Самые популярные утилиты командной строки для создания архива сайта — это Wget и Wpull.
Wget
Wget — это пакет свободного программного обеспечения для извлечения файлов с помощью HTTP, HTTPS, FTP и FTPS и других наиболее широко используемых интернет-протоколов. Это неинтерактивный инструмент командной строки, поэтому его можно легко вызывать из скриптов, терминалов и т.д.
Wget имеет множество функций, облегчающих получение больших файлов или зеркалирование целых сайтов в Интернете или FTP, в том числе:
- Может возобновлять прерванную загрузку, используя REST и RANGE.
- Может использовать подстановочные карты в именах файлов и рекурсивного зеркалирования каталогов.
- Опционально преобразует абсолютные ссылки в загруженных документах в относительные так, что загруженные документы могут ссылаться друг на друга локально.
- Поддерживает HTTP-прокси.
- Поддерживает HTTP cookies.
- Поддерживает постоянные HTTP-соединения.
- Неавторизованная / фоновая работа скрипта.
- Использует локальные временные метки файлов для определения необходимости повторной загрузки документов при зеркалировании
Wget распространяется под лицензие�й GNU General Public License.
Wpull
Wpull — это Wget-совместимый (или ремейк/клон/замена/альтернатива) веб-загрузчик и краулер. Краулер — это интернет-бот, который систематически просматривает интернет и обычно используется поисковыми системами для веб-индексации. Веб-краулеры копируют страницы для обработки поисковой системой, которая индексирует загруженные страницы, чтобы пользователи могли осуществлять более эффективный поиск. Краулеры могут проверять гиперссылки и HTML-код. Они также могут использоваться для веб-скреппинга и программирования на основе данных.
Примечательные особенности Wpull:
- Написан на Python и доступен к модификации.
- Интегрируется с PhantomJS и youtube-dl (экспериментально).

У этих утилит есть режим рекурсивной выгрузки всех страниц, он задается опцией “-r”. В самом простом варианте достаточно выполнить команду, подобную этой.
Дальнейшие шаги
После успешной архивации сайта:
- Проверьте результат: Откройте сохраненные файлы в браузере
- Создайте резервную копию: Скопируйте в несколько мест (локально + облако)
- Изучите продвинутые техники: Полное руководство по wget
- Узнайте о форматах: WARC и WACZ
Связанные материалы
- Быстрый старт: архивация за 5 минут - для начинающих
- Archive.ph: полное руководство - архивация отдельных страниц
- Экстренная архивация - когда счет идет на часы
- Использование утилиты wget - детально о командной строке
- Форматы архивов - WARC, WACZ и другие